
우리는 주사위 굴리기, 동전 던지기, 카드 게임 등을 통해 확률 개념을 많이 접한다.
주사위 굴리기와 같은 무작위 사건 사례에서 각 사건의 발생 확률은 1/6로 모두 같다. 이를 수식으로 표현하면,

위와 같이 나타낼 수 있고, 이를 풀어쓰면 "주사위를 굴려 1이 나올 확률은 6분의 1이다."이다.
파이썬에서 NumPy를 이용하여 동일한 가중치를 가진 무작위 사건을 생성하는 방법은 다음과 같다.
np.random.randint(1,7)radint는 파이썬의 인덱싱 방식처럼 시작점을 포함하고 마지막 지점을 제외한다. 그래서 1부터 6까지 값을 얻으려면 1에서 시작해서 7로 끝나야 한다. 수학적 용어로는 반개 구간(half-open interval)이라고 한다.
주사위를 10번 굴렸을 때의 각 사건에 대한 histogram과 주사위를 1000번 굴렸을 때의 각 사건에 대한 histogram을 그려 비교해보자.
np.histogram은 연속적인 수치를 버킷에 담아 그리도록 디자인되었다. 주사위 눈은 이산적인 값이므로, 눈 주위를 감싸는 버킷을 만들도록 하였다. 예를 들어, 0.5부터 1.5까지 담는 버킷으로 주사위 눈 1을 표현하도록 한다.
few_rolls = np.random.randint(1,7,size=10)
many_rolls = np.random.randint(1,7,size=1000)
few_counts = np.histogram(few_rolls, bins=np.arange(.5, 7.5))[0]
many_counts = np.histogram(many_rolls, bins=np.arange(.5, 7.5))[0]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 3))
ax1.bar(np.arange(1,7), few_counts)
ax2.bar(np.arange(1,7), many_counts);
위의 코드를 통해 알 수 있는 점은, 실제 정답에 가까운 답을 얻기 위해서는 더 많은 샘플이 필요하다는 것이다.
단순 사건과 복합 사건
복합 사건(compound event)의 확률은 단순 사건의 발생 횟수를 세거나 개별 단순 사건의 확률을 모두 더해 구할 수 있다. 예를 들어, 주사위를 던져 홀수가 나올 확률을 구할 때에 홀수를 구성하는 세 가지 경우는 서로 겹치지 않으므로 개별 사건의 확률을 더해서 구할 수 있다.

확률이 가진 주요 성질은 다음과 같다.
- 모든 가능한 단순 사건 확률의 합은 1이다.
- 어떤 사건이 발생하지 않을 확률은 1에서 그 사건이 발생할 확률은 뺀 것과 같다.
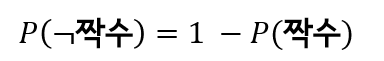
- 단순하지 않은 사건도 있다. 단순 사건의 조합은 복합 사건이다.
- 복합 사건은 재귀적이다. 여러 개의 복합 사건으로 새로운 복합 사건을 만들어 낼 수 있다.

독립
주사위 두 개를 굴리는 경우에, 두 주사위는 대화하거나 서로의 행동에 영향을 받지 않는다. 첫 번째 주사위를 굴려 1이 나왔다고 해서 다른 주사위의 값들이 가진 확률이 변하지는 않는다. 이때 두 사건은 서로 독립이라고 한다.

독립 확률은 필요충분조건을 만족한다.
- 두 사건이 독립이라면, 각 확률을 곱해서 두 사건이 모두 발생할 결합 확률을 구할 수 있다.
- 확률들을 곱했을 때 경우의 수를 세는 방식으로 계산한 것과 동일한 확률을 얻었다면, 이 사건들은 서로 독립이다.
조건부 확률
다음과 같이 동전과 항아리로 하는 두 단계의 게임이 있다고 하자.
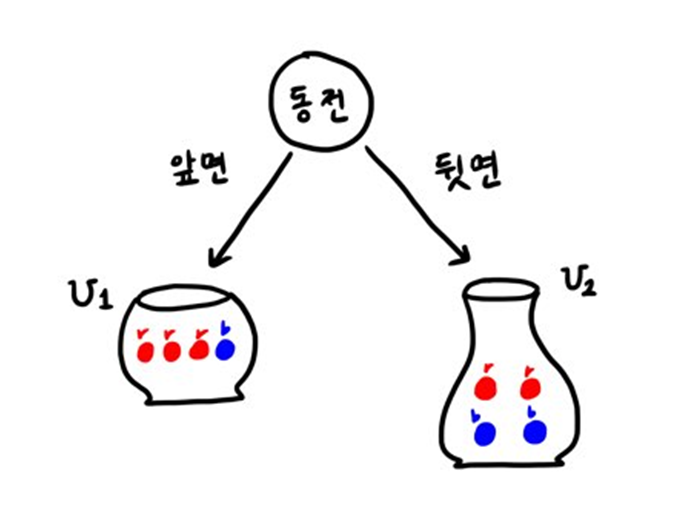
첫 번째 항아리 U1에는 빨간 공이 세 개, 파란 공이 한 개 들어있고, 두 번째 항아리 U2에는 빨간 공이 두 개, 파란 공이 두 개 들어있다. 동전을 하나 던져 앞면이 나오면 U1에서 공을 고르고, 뒷면이 나오면 U2에서 공을 고른다.
이미 동전을 던져 앞 면이 나왔을 때에 빨간 공을 뽑는 확률은 다음과 같다.

조건부(머신 러닝과 통계학에서 주로 사용하는 표현)는 발생할 수 있는 단순 사건의 하위 집합에 문제를 한정한다. 세로 막대 |는 "x가 일어났을 때(given)"라는 의미이다.
여기서 동전을 던지는 것이 항아리 U1 사건에 영향을 주지 않는 독립 사건이므로, 항아리 U1에서 빨간 공을 뽑을 확률은 다음과 같다.
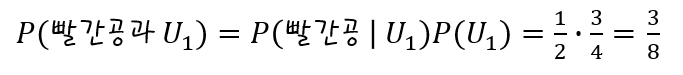
확률 분포
사건과 확률 간 매핑을 확률 분포(probability distribution)이라고 한다.
공정한 주사위 눈처럼, 어떤 사건의 집합이 같은 확률 값을 공유한다면 이것을 균등 분포(uniform distribution)라고 한다.
동전을 던지는 횟수를 늘려가며 던졌을 때 앞이 나온 횟수를 세어 확률 분포를 그려보자.
import scipy.stats as ss
b = ss.distributions.binom
for flips in [5, 10, 20, 40, 80]:
# 동전을 수없이 던지면 확률 .5를 가지는 이항분포가 그려집니다.
success = np.arange(flips)
our_distribution = b.pmf(success, flips, .5)
plt.hist(success, flips, weights=our_distribution)
plt.xlim(0,55);
횟수는 정수이기 때문에 계단처럼 각진 그래프가 그려진다. 이 그래프를 부드러운 곡선으로 바꾸어 보면 다음과 같은 결과가 나온다.
b = ss.distributions.binom
n = ss.distributions.norm
for flips in [5, 10, 20, 40, 80]:
# 동전 던지기
success = np.arange(flips)
our_distribution = b.pmf(success, flips, .5)
plt.hist(success, flips, weights=our_distribution)
# 정규분포로 이항분포를 근사합니다.
# 평균과 표준편차를 설정합니다.
mu = flips * .5,
std_dev = np.sqrt(flips * .5 * (1-.5))
# 정규분포를 위해 x와 y 포인트를 설정해야 합니다.
# 함수에 xs를 입력하고 이를 통해 ys를 얻습니다.
norm_x = np.linspace(mu-3*std_dev, mu+3*std_dev, 100)
norm_y = n.pdf(norm_x, mu, std_dev)
plt.plot(norm_x, norm_y, 'k');
plt.xlim(0,55);
동전 던지기 횟수가 늘어날수록 측정값의 정확도가 개선된다. 위 그래프에서 분모가 커질수록 변화량이 더 작아져 값이 점진적으로 변화하는 것을 알 수 있다. 계단 모양의 시퀀스를 부드러운 곡선으로 대체하여 표현하였는데, 이 곡선을 종형 곡선(bell-shaped curves)이라고 한다. 이 종형 곡선은 정규 분포(normal distribution)의 형태를 띠고 있다.
정규 분포의 세 가지 특징
- 분포의 중간점이 가장 가능성이 높은 값이다.
- 중간점을 기준으로 분포는 대칭을 이룬다.
- 중간점에서 멀어질수록 값은 더 많이, 빨리 감소한다.
Reference
마크 페너, <머신러닝을 다루는 기술 with 파이썬, 사이킷런>(길벗, 2020)

'AI' 카테고리의 다른 글
| [Machine Learning] 범주 예측: 분류 모델 생성 과정 (0) | 2020.10.21 |
|---|---|
| [Machine Learning] 다변량 데이터(multivariate data) 나타내기 (0) | 2020.10.17 |
| [Machine Learning] 선형 결합, 가중 평균, 제곱합, 오차 제곱합 (0) | 2020.10.14 |
| [Machine Learning] 머신러닝이란? (0) | 2020.10.09 |