목차
목차를 클릭하면 해당 게시글로 더 빠르게 접근할 수 있습니다.
자연어 처리(Natural Language Processing, NLP) 기술
'빅데이터'란, 다양한 원천에서 얻어지는 방대한 양의 데이터를 의미한다. 디지털 세상에 새로운 채널과 기술이 확산함에 따라 엄청난 양의 정보가 실시간으로 쏟아져 내린다. 사람들은 스마트폰을 통해 음성 인식 기능을 사용하거나 SNS에서 콘텐츠를 업로드하고, 물건을 구매하거나 OTT(Over the Top Service)를 통해 영상 콘텐츠를 스트리밍 한다. 이러한 액션들 하나하나가 데이터가 되고, 기존 시스템으로는 처리하기 어려울 정도의 많은 양의 데이터가 지금, 이 순간에도 만들어지고 있다.
전문가들은 이 데이터들 중 90% 가량은 구조화되지 않은 데이터, 비정형 데이터라고 말한다. 웹 크롤링, 음성 녹음 파일, SNS상의 콘텐츠 등에서 얻어지는 데이터들은 거의 모두 비정형 데이터에 해당하는 것이다.

이렇게 끊임없이 생성되는 데이터를 수집, 저장, 처리 및 분석하기 위해 우리는 자연어 처리(Natural Language Processing, NLP) 기술을 활용한다. NLP 기술은 컴퓨터와 인간 사이의 상호 작용하는 기술로, 인공지능의 핵심 기능 중 하나이다. 여기서 '자연어'는 우리가 사용하는 언어를 말한다. 인간들은 지역에 따라 다른 표현을 사용하기도 하고, 사용하는 언어 습관 또한 다양하며 문법에 맞지 않는 문장도 맥락을 통해 의사소통하기도 한다. 그러나 컴퓨터가 사실상 무질서한 인간의 언어를 올바르게 이해하는 것은 쉽지 않다. 이를 가능하기 위해 등장한 기술이 'NLP 기술'이다.
1950년대부터 기계 번역과 같은 자연어 처리 기술이 연구되기 시작했는데, 1990년대 이후에는 대량의 말뭉치(corpus) 데이터를 활용하는 기계학습 기반 및 통계적 자연어 처리 기법이 주류를 이뤘다. 최근에는 딥러닝과 딥러닝 기반의 자연어 처리가 방대한 텍스트로부터 의미 있는 정보를 추출하고 활용하기 위한 언어 처리 연구 개발이 전 세계적으로 활발히 진행되고 있다.
그렇다면 NLP는 어떤 원리로 작동하는 기술일까?

우선, NLP를 이해하기 위해선 인공지능을 먼저 이해할 필요가 있다.
컴퓨터 스스로 인간과 유사하게 학습 및 추론할 수 있는 능력을 갖추었을 때 인공지능이라고 부른다. 그리고 이 인공지능을 실현시킬 수 있는 기술이 머신러닝 기술이며, 머신러닝 기술을 실현시킬 수 있는 수많은 알고리즘 중 하나가 딥러닝 알고리즘이다.
NLP는 인공지능의 한 범주이기도 하지만, 머신러닝과 딥러닝의 일정 부분 교집합을 갖는 기술이기도 하다. 즉, NLP 알고리즘이란 컴퓨터가 인간의 언어를 입력받아 이를 이해하고, 분석하여 최적의 결괏값을 찾아내는 과정을 반복하는 프로그램으로 볼 수 있다. 해당 절차를 추상화해서 표현하면 아래 구조와 같다.

비정형 데이터 형식으로 들어오는 음성/텍스트 데이터의 입력값을 형태소 분석기와 구문 분석기를 활용하여 분석이 가능한 형태로 결과값으로 변환하는 과정이 필요하다.
맨 처음 음성 또는 텍스트 데이터를 입력받은 NLP 알고리즘이 해당 발화에 대한 분석을 하는 과정을 "자연어 이해"라고 하며, 분석 과정을 거친 후 최적의 결과값을 도출하는 것을 "자연어 생성(NLG)"라고 부른다.
NLP 활용 비즈니스 및 서비스
자연어 처리 기술은 음성의 인식, 내용 요약, 언어 번역, 인간의 감정 분석, 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류), 자동 Q&A 시스템, 챗봇과 같은 서비스에서 다방면으로 사용되고 있다.
각각의 서비스는 어떤 기능을 하고, 어떻게 활용되는지 자세히 살펴보도록 하자.
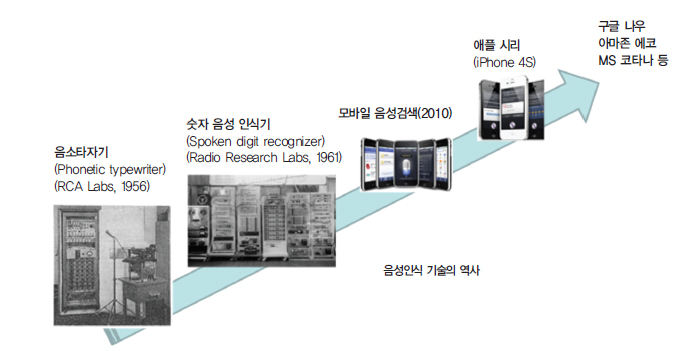
음성 인식 기술
음성은 사람 간의 가장 자연스러운 의사소통 방식이다. 음성 인식 기술은 이미 스마트폰, 자동차, 콜센터 등 현재 우리 생활의 많은 부분에 녹아들어서 서비스화되고 있다.
음성인식 기술은 사람이 일상생활에서 발성한 모든 내용을 그대로 받아 적으며(dictation), 외국인이 자기 나라 언어로 발성한 것을 그대로 우리말로 통역해 주거나 그 반대로 해주는 자동통역(automatic interpretation), 원어민과 대화하듯이 영어 회화를 가르쳐주는 컴퓨터 언어 교사(language tutor), 말만 하면 알아서 일정관리 및 대화 상대 등을 해주는 지능형 비서 등의 개발을 궁극의 목표로 한다.
텍스트 요약
텍스트 요약은 상대적으로 큰 원문을 핵심 내용만 간추려서 상대적으로 작은 요약문으로 변환하는 것을 말한다. 글을 읽고 이해하는 시간을 단축해준다는 점에서 여러 분야에서 필요로 하는 기술이다.
텍스트 요약은 원문에서 중요한 핵심 문장 또는 단어구를 몇 개 뽑아서 이들로 구성된 요약문을 만드는 방법인 추출적 요약과 원문에 없던 문장이라도 핵심 문맥을 반영한 새로운 문장을 생성해서 원문을 요약하는 방법인 추상적 요약으로 구분할 수 있다.
이러한 방법으로 신문 기사나, 초록, 보고서 등 문서내 주요 문장들의 가장 중요한 부분을 선별하고 각 문장의 중요도를 발췌하여 요약된 정보를 제공하는 자동 요약 서비스가 생겨나기도 했다. 자동 요약 서비스는 많은 정보를 접하는 곳에서 빠르게 정보를 선별해야 하는 업무에 적용하기에 좋다.

언어 번역
Google 번역, 네이버의 파파고번역, 카카오의 i 번역 등 nlp 기술을 활용한 수많은 언어 번역 프로그램들이 존재한다. 다양한 번역 서비스가 어플로 등장하기 시작하면서 실시간으로 번역을 실행할 수도 있게 되었다. 아직 완벽하게 자연스러운 번역은 아니지만 그 기술은 계속해서 발전할 전망이다.
실제로, 딥덥(deepdub)이라는 스타트업이 지난 12월 17일에 딥러닝으로 음성을 번역하는 솔루션에 대한 영상을 발표했다. 영어를 기반으로 프랑스어, 독일어, 스페인어 등 6개 언어로 자동 통역 서비스를 제공하는데, 특이한 건 목소리 원본의 음색이 바뀌지 않는다는 점이다.
딥러닝을 기반으로 하다보니 아직은 걸음마 수준이라고는 하지만 콘텐츠의 양이 늘어날수록 학습 능력이 더 나아질 것이라고 기대된다. 한국에서는 네이버가 이 분야를 선도하고 있는데, 클로바를 기반으로 한 통역과 더빙을 제공하고 있다고 한다.
딥덥에서 발표한 영상을 직접 보면 더 신기하다...
감성 분석(Sentiment Analysis)
감성 분석(Sentiment Analysis)이란 텍스트에 들어있는 의견이나 감성, 평가, 태도 등의 주관적인 정보를 컴퓨터를 통해 분석하는 과정이다. 주로 문서(문장)의 어떤 부분에 의견이 담겨있는지를 정의(Opinion definition)하고, 모아진 의견을 요약(Opinion summerization)하는 단계를 거치게 된다.
감성 분석은 다양한 분야에서 사용되고 있는데, 기업 내부적으로는 고객 피드백, 콜센터 메시지 등과 같은 데이터를 분석하며 외부적으로는 기업과 관련된 뉴스나 SNS 홍보물 등에 달린 댓글의 긍/부정을 판단하는 곳에 사용되고 있다. 개인 단위에서는 영화를 보기 전에 리뷰를 참고하는 것과 같이 특정 제품이나 서비스를 이용할지를 결정하는 데에 사용할 수 있다.
텍스트 분류(Text Classification)
텍스트 분류(Text Classification)는 텍스트를 입력으로 받아, 텍스트가 어떤 종류의 범주(Class)에 속하는지를 구분하는 작업을 말한다. 가령, 스팸 메일 분류를 해본다고 하자. 스팸 메일 분류는 일반 메일과 스팸 메일이라는 두 개의 범주를 정해놓고 입력받은 텍스트를 두 개의 클래스 중 하나로 분류하는 작업이 될 것이다.
스팸 메일 분류 이외에도 영화 리뷰와 같은 텍스트를 입력받아서 이 리뷰가 긍정 리뷰인지 부정 리뷰인지를 분류하는 '감성 분석', 입력받은 텍스트로부터 사용자의 의도를 질문, 명령, 거절 등과 같은 클래스로 분류하는 '의도 분석'과 같은 문제들에 응용될 수 있다.
질의응답(Question Answering, QA)
요즘은 지문(context)과 질문(question)을 보고 답(answer)을 생성하는 연구인 TextQA 모델에 대한 연구가 많이 진행되고 있다. 질의응답(Question Answering, QA)라고도 하는 이 기술은 다른 NLP 기술들과 마찬가지로 여러 가지 분야에서 필요로 하지만 아직 대중화된 서비스로 제공되고 있다고 보기는 힘들다.
그렇지만 QA 모델을 이용한 서비스 발굴은 계속 진행 중인 것으로 보인다. 대표적으로 페이스북에서 공개한 Babi QA 셋을 통해 학습 데이터셋을 구축해볼 수 있고, BERT를 이용한 MRC(기계 독해 이해력) 테스트인 스쿼드(SQuAD, Stanford Question Answering Dataset)가 제공되어 있다고 한다.
특히 한국어 표준 데이터 코쿼드 2.0은 AI가 표나 리스트 형태에 담긴 정보도 읽어 답변할 수 있게끔 표준데이터 범위도 확대했다. 정보 4만 건과 질의응답 세트 10만 건으로 구성되어 있다. 10만 건의 질의응답 세트 중 약 9만 건은 AI 학습용으로 사용되고, 1만 건은 개발된 AI의 성능 평가용으로 사용된다.
출처 : 인공지능신문(http://www.aitimes.kr)

챗봇(Chatbot)
AI 기반 챗봇은 기계어와 자연어 처리를 활용하여 고객의 숨은 의도를 파악하고, 상호작용할 때 이전의 대화 기록을 활용하며, 질문에 자연스럽고 인간적인 방식으로 답변해주는 서비스이다. 페이스북 메신저, 웹 사이트, 문자 메시지 등등 점점 더 많은 브랜드에서 챗봇을 활용하고 있다. 요즘은 거의 모든 기업이나 브랜드에서 챗봇을 도입하고 있다고 봐도 무방할 정도다.
다음은 'Hello Digital'에서 선정한 2020년 BEST 챗봇 TOP7이다
- Watson Assistant : 자기 학습으로 발전하는 챗봇
- Bold360 : 특허받은 "검증된" 챗봇
- Rulai : 딥러닝으로 더 깊은 고객 이해를.
- LivePerson : 데이터 기반 챗봇의 끝판왕
- Inbenta : 규모 있는 기업을 위한 챗봇
- Ada : Medium, Shopify, MailChimp가 선택한 챗봇
- Vergic : 하이브리드 챗봇
www.hellodigital.kr/blog/7-best-ai-chatbots/
2020년 BEST 챗봇 TOP7 📙 - HelloDigital ㅣ 블로그
AI의 발전으로 인해, 사람이 조금만 개입하더라도 완벽한 수준으로 고객을 응대할 수 있습니다. 인건비 절감, 업무시간의 극대화, 쉬운 난이도와 경제적 예산 등의 이점을 얻을 수 있는 챗봇 활
www.hellodigital.kr
NLP 활용 API 솔루션
NLP 시장은 스마트 기기 사용 증가와 클라우드 기반 솔루션 채택 증가, 고객 서비스 개선을 위한 NLP 기반 애플리케이션의 증가, 의료 산업에 대한 기술 투자 증가 등에 따라 무섭게 성장하고 있다. 의료 산업이나 법률, 교육계 등 다양한 분야에서 인간 언어의 의미와 뉘앙스를 이해할 수 있는 알고리즘의 필요성이 제고되면서 NLP 솔루션을 채택하는 사례가 증가하고 있다.
응용 프로그램에서 필요로 하는 주 NLP 기능은 기계 번역, 정보 추출, 자동 요약, 질문 답변, 텍스트 분류, 감정 분석 및 기타(스팸 인식 및 언어 감지 등)가 있다. 이러한 기능들은 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료인 '말뭉치'의 양과 그 학습량에 따라 AI의 정확도가 좌지우지되므로 각국은 어절을 구축하고 응용 솔루션이나 AI 개발에 국가 경쟁력 차원에서 힘쓰고 있는 실정이다.
국내에서도 다양한 NLP 구축 솔루션이 제공되고 있다.
코버트(KorBERT)
지난해 6월 과기정통부의 소프트웨어 분야의 국가 혁신기술 개발형 연구개발 과제인 혁신성장동력 프로젝트로 추진 중인 엑소브레인 사업에서 한국전자통신연구원(ETRI)은 최첨단 한국어 언어 모델 '코버트(KorBERT)'를 공개했다. 구글의 BERT 언어 표현 방법을 기반으로 더 많은 한국어 데이터를 넣어 만든 언어 모델과 한국어의 '교착어' 특성까지 반영해 만든 언어 모델이다.
공공 인공지능 오픈 API·DATA 서비스 포털
과학기술정보통신부의 R&D 과제를 통해 개발한 다양한 인공지능 기술 및 데이터를 누구나 사용할 수 있도록 제공
aiopen.etri.re.kr
언어처리를 위한 딥러닝 기술을 개발하기 위해서는 텍스트에 기술된 어절을 숫자로 표현해야 한다. 이를 위해 그동안 언어를 활용한 서비스를 개발하는 기관에서는 주로 구글의 다국어 언어 모델 버트(BERT)를 사용했다. 그동안 구글은 40여 만 건의 위키백과 문서 데이터를 활용해 한국어 언어 모델을 개발해왔는데, ETRI 연구진은 여기에 23기가에 달하는 10년간의 신문기사와 백과사전 정보를 더해 45억 개의 형태소를 학습시켜 구글보다 많은 한국어 데이터를 기반으로 언어 모델을 개발했다.
ETRI는 한국어에 최적화된 언어 모델이 '전처리 과정에서 형태소를 분석한 언어 모델', '한국어에 최적화된 학습 파라미터', '방대한 데이터 기반' 등의 특징으로 인해 구글과는 차별성이 있다. 개발된 언어 모델은 성능을 확인하는 5가지 기준에서 구글이 배포한 한국어 모델보다 성능이 평균 4.5%가량 우수했다고 한다. 특히, 단락 순위화(Passage Ranking) 기준에서는 7.4%나 높은 수치를 기록했다.
카이(khaiii)
카카오는 2018년 말부터 딥러닝 기반 형태소 분석기 '카이(khaiii)'를 오픈소스로 제공하고 있다. 딥러닝을 통해 학습한 데이터를 활용해 형태소를 분석하는 모델이다. 딥러닝 기술 중 하나인 CNN(Convolution Neural Network)을 이용해 음절 기반으로 형태소를 분석하는 방법을 채택했다고 전해진다.
kakao/khaiii
Kakao Hangul Analyzer III. Contribute to kakao/khaiii development by creating an account on GitHub.
github.com
세종 코퍼스를 기반으로 데이터의 오류를 수정하고 카카오에서 자체 구축한 데이터를 추가해 85만 문장, 1003만 어절의 데이터를 학습하여 정확도를 높였다. 또 딥러닝 과정에서 C++ 언어를 적용해 일반적으로 딥러닝에 쓰이는 GPU를 사용하지 않고도 빠른 분석 속도를 구현했다.
카이에 관한 더 상세한 정보는 위의 깃허브에서 확인할 수 있으며, 누구나 무료로 이용 가능하다. 주로 자연어 처리 응용 서비스의 기반 기술로 사용되며, 정보 검색, 기계 번역, 스마트 스피커나 챗봇 등 여러 서비스에서 사용될 수 있다.
NAVER
네이버는 모바일 상에서의 검색이 일상화된 이용자들을 위해 AI 기술 기반 검색어 교정 시스템인 'AIQSpell' 개발에 힘써왔다. 딥러닝을 비롯한 최신의 AI 기술을 활용해 기존의 검색어 교정 시스템을 대체한 것이다. 이로 인해 오타 질의들에 대한 검색어 교정량이 43%나 증가하였고, 비교적 긴 질의에서 발생하는 오타를 알맞은 검색어로 교정하는 비율이 대폭 증가하였다.
뿐만 아니라 최신 AI 기술의 적용으로 자동완성 서비스 역시 대폭 개선되었다. 개편된 네이버 자동완성 모델은 오타가 발생했을 가능성, 순서가 뒤집혔을 가능성, 그리고 사용자가 많이 찾는 검색어일 가능성 등을 조합해 추천 검색어 후보들의 최종 점수를 계산하여 적절한 검색어를 제공한다. 이로써 사용자가 검색어를 구체적으로 입력하지 않더라도 이전보다 더욱 정확한 검색 결과를 얻을 수 있게 되었다.
마치며
자연어 처리 기술의 A부터 Z까지 모든 것을 다 포스팅하고 싶었으나, 생각보다 NLP 기술의 시장과 테크닉이 방대하다는 것을 깨달았다. 그저 딥러닝의 한 영역인 줄로만 알았는데, 딥러닝의 영역이 아닌 인공지능의 한 영역으로써 큰 부분을 차지하고 있더라는 것이다. 그만큼 자연어 처리 기술을 이용한 기능도 많이 구현되고 있고 우리 삶이 그 만큼 더 살기 편해지는 것 같다.
인공지능의 발전 방향이 무궁무진하고 그 속도가 어마어마한 만큼 자연어 처리 기술의 연구도 활발히 이루어지고 있고, 또 새로운 기술과 서비스를 선보일 수도 있다. 데이터 엔지니어 및 서비스 기획을 희망하는 학생으로서 자연어 처리 기술에 더 관심을 갖고 각종 프로젝트를 해보면서 공부하면 좋겠다는 생각을 했다.
Reference
<딥 러닝을 이용한 자연어 처리 입문>, 유원준, WikiDocs, 2020
"[스페셜리포트] 자연언어처리(NLP) 무엇인가... 그 기술과 시장은?", 인공지능신문, 2020.01.02, https://www.aitimes.kr/news/articleView.html?idxno=15036
[스페셜리포트] 자연언어처리(NLP) 무엇인가... 그 기술과 시장은? - 인공지능신문
자연 언어 처리(Natural Language Processing, 이하 NLP)는 컴퓨터와 인간 언어 사이의 상호 작용하는 기술로 인공지능의 핵심 기능 중 하나이다. 1950년대부터 기계 번역과 같은 자연어 처리 기술이 연구
www.aitimes.kr
"챗봇에서 활용되는 NLP 알고리즘의 기초적 원리와 제품 기획의 방향", Contenta M, https://magazine.contenta.co/2020/09/%EC%B1%97%EB%B4%87-%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98npl/
챗봇에서 활용되는 NLP 알고리즘의 기초적 원리와 제품 기획의 방향
콘텐츠 마케팅 솔루션 콘텐타 매거진
magazine.contenta.co
'IT Trends' 카테고리의 다른 글
| [IT Trends] 해커톤(Hackathon)에 참가해보자! (0) | 2021.01.16 |
|---|---|
| [IT Trends] 미국에서 주목받는 차세대 홈트레이닝 겨냥 스타트업 (0) | 2020.12.20 |
| [IT Trends] 암호화폐와 블록체인 기술 (2) | 2020.11.18 |
| [세레나데] 손 쓰지 않고도 코딩이 가능해진다? (0) | 2020.10.08 |